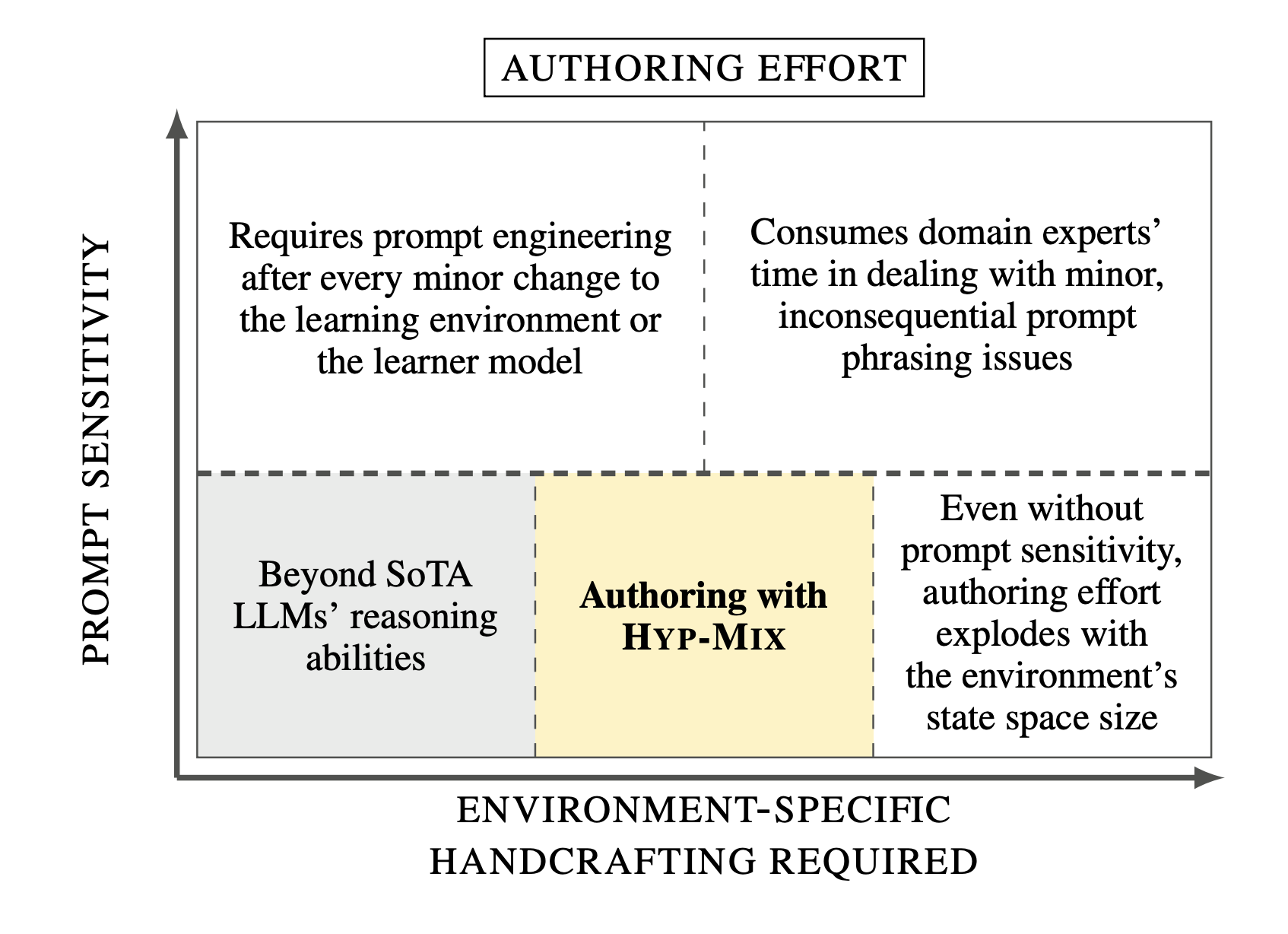
Can LLMs Reliably Simulate Human Learner Actions? A Simulation Authoring Framework for Open-Ended Learning Environments
Amogh Mannekote, Adam Davies, Jina Kang, Kristy Elizabeth Boyer
arXiv preprint arXiv:2410.02110, 2024
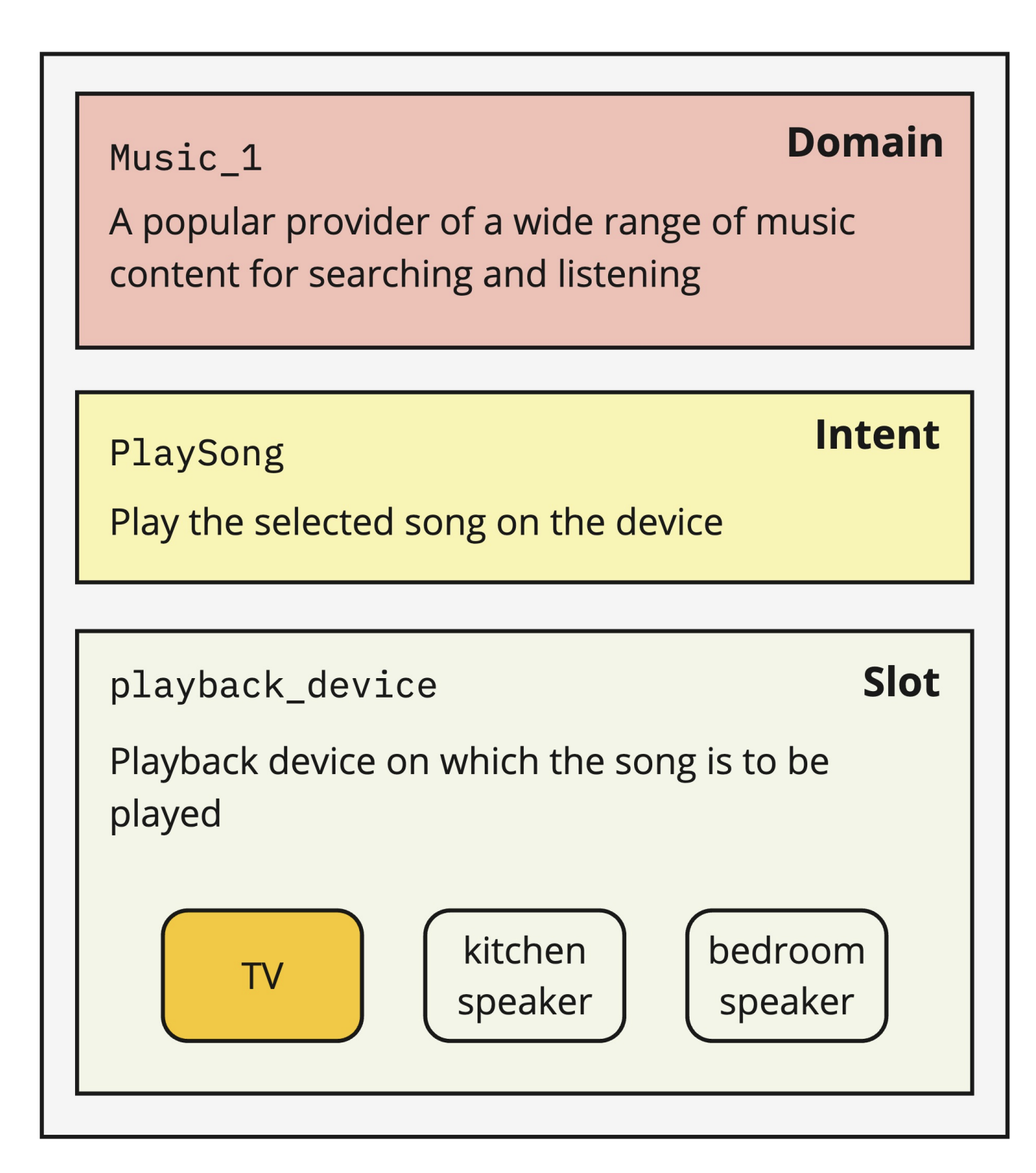
IndirectRequests: Making Task-Oriented Dialogue Datasets More Natural by Synthetically Generating Indirect User Requests
Amogh Mannekote, Jinseok Nam, Ziming Li, Kristy Elizabeth Boyer, Bonnie J. Dorr
arXiv preprint arXiv:2406.07794v1, 2024
Examining LLM Prompting Strategies for Automatic Evaluation of Learner-created Computational Artifacts
Xiaoyi Tian, Amogh Mannekote, Carly Solomon, Yukyeong Song, Christine Fry Wise, Tom McKlin, Joanne Barrett, Kristy Elizabeth Boyer and Maya Israel
Poster in Educational Data Mining, 2024
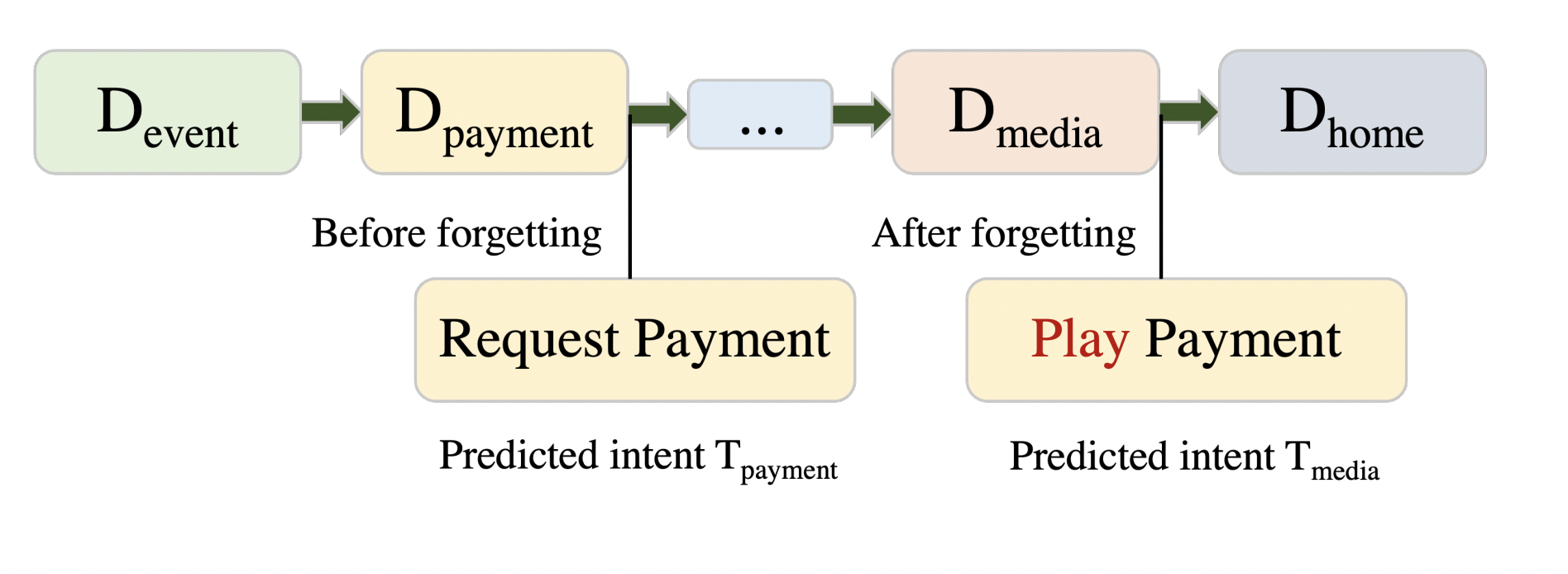
Can Similarity-Based Domain-Ordering Reduce Catastrophic Forgetting for Intent Recognition?
Amogh Mannekote, Xiaoyi Tian, Kristy Elizabeth Boyer, Bonnie J. Dorr
arXiv preprint arXiv:2402.14155, 2024
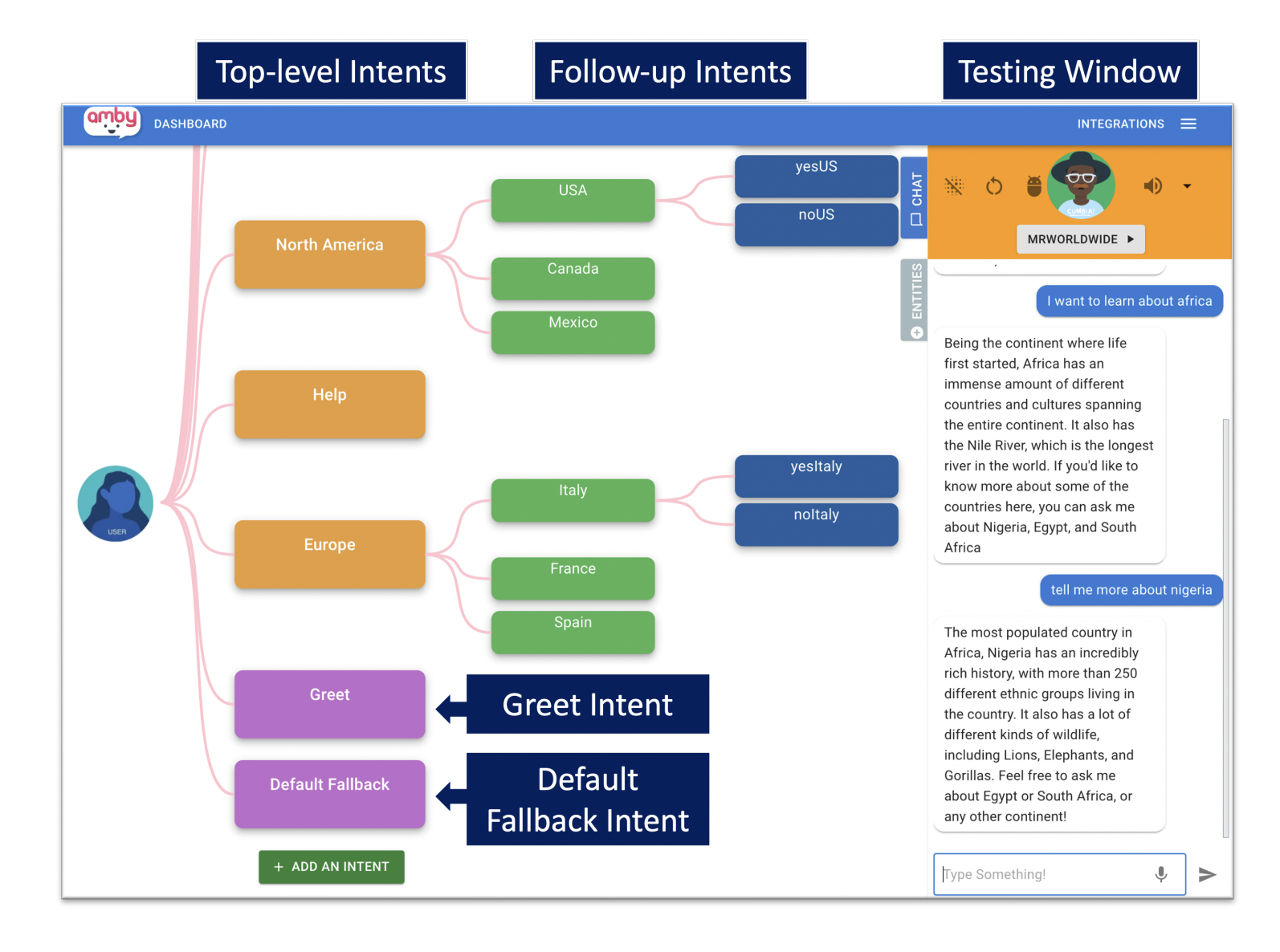
Exploring Usability Issues in Instruction-Based and Schema-Based Authoring of Task-Oriented Dialogue Agents
Amogh Mannekote, Mehmet Celepkolu, Joseph B. Wiggins, Kristy Elizabeth Boyer
CUI 2023: Proceedings of the 5th International Conference on Conversational User Interfaces, 2023
Towards a Neural Era in Dialogue Management for Collaboration: A Literature Survey
Amogh Mannekote
arXiv preprint arXiv:2307.09021, 2023
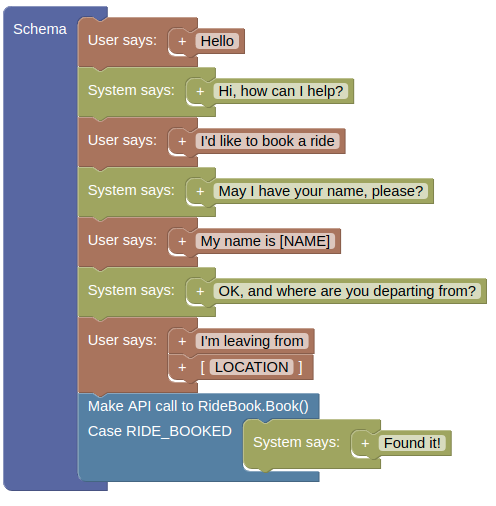
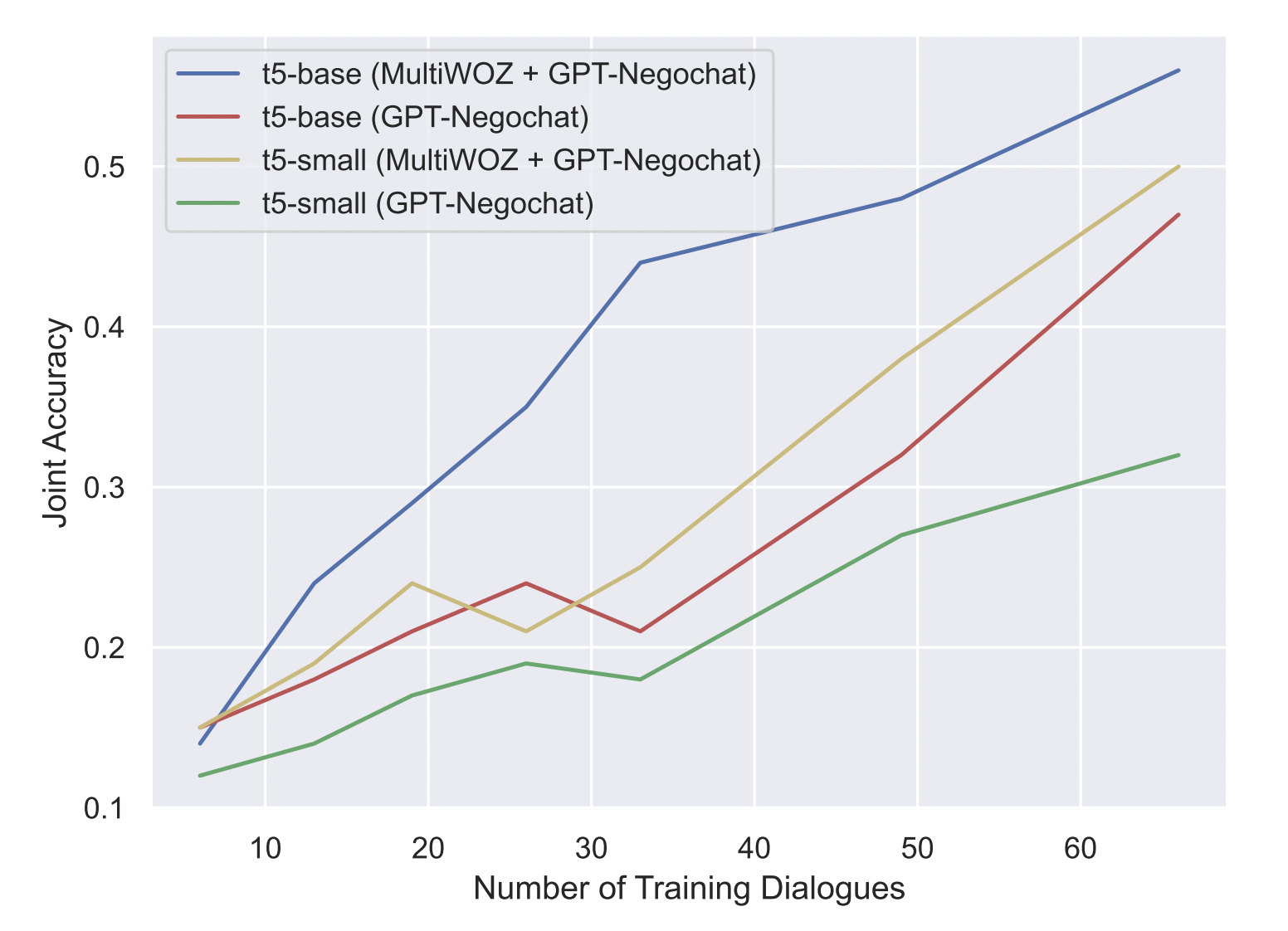
Agreement Tracking for Multi-Issue Negotiation Dialogues
Amogh Mannekote, Kristy Elizabeth Boyer, Bonnie J. Dorr
arXiv preprint arXiv:2307.06524, 2023
Don't Just Paste Your Stacktrace: Shaping Discussion Forums in Introductory CS Courses
Amogh Mannekote, Mehmet Celepkolu, Aisha Chung Galdo, Kristy Elizabeth Boyer, Maya Israel, Sarah Heckman, Kristin Stephens-Martinez
Proceedings of the 53rd ACM Technical Symposium on Computer Science Education, 2022